
Take responsibility: Another DO and another DON’T when using AI for text analysis.
🤔 Can we solve all or some of our evaluation and research questions by just delegating them to an AI? In this second post in a series of AI Do's and Don'ts, Steve Powell argues how wrong this picture is.
If you’ve worked in project monitoring, you’ll know that the answer to the question “how many packages were delivered to recipient” isn’t as easy as it sounds. Sometimes we have to reach agreement about difficult edge cases and what to do with them: a combination of skill, trust and arithmetic. We agree or learn how to return an answer which is as fair as possible, bearing in mind how management will understand it, without dragging them down into the weeds of the workarounds and sub-calculations involved. Management know they can trust us to provide and communicate reliable data they will understand correctly.
But what about the questions “was package delivery efficient?” or even “was the delivery project effective and sustainable”? There is no even vaguely off-the-shelf way to answer them.
Can we solve all or some of our evaluation and research questions by just delegating them to an AI?
This is second in a series of posts. In this post, I’m going to argue how wrong this picture is:

What goes on in the black box? Does anyone know?
- If we haven’t agreed amongst ourselves exactly how to answer the question, what we need is the collective construction of a transparent workflow which not only ultimately gives an answer but first gives the question more precise meaning by showing a way to answer it in this particular context. Why do we assume that the answer the AI will certainly blurt out all on its own can somehow circumvent the need for that collective construction?
How did the AI reach its conclusions? Even if it tries to tell us, is that explanation true?
- If it was really as clever as a human (but faster), why would we trust that human? (See my last post.)
Here’s a sketch which I think better reflects in general how (evaluation) research questions get asked and answered. It is intended to put into a broader context the question what’s wrong with the monolithic, black-box use of AI . (In terms of how AI can be applied, I am mostly interested with its application to one important part of this kind of workflow, namely processing interview and report data. But we are already seeing tools for extending the use of AI in evaluation beyond that task. One example would be our own AI interviewer.)
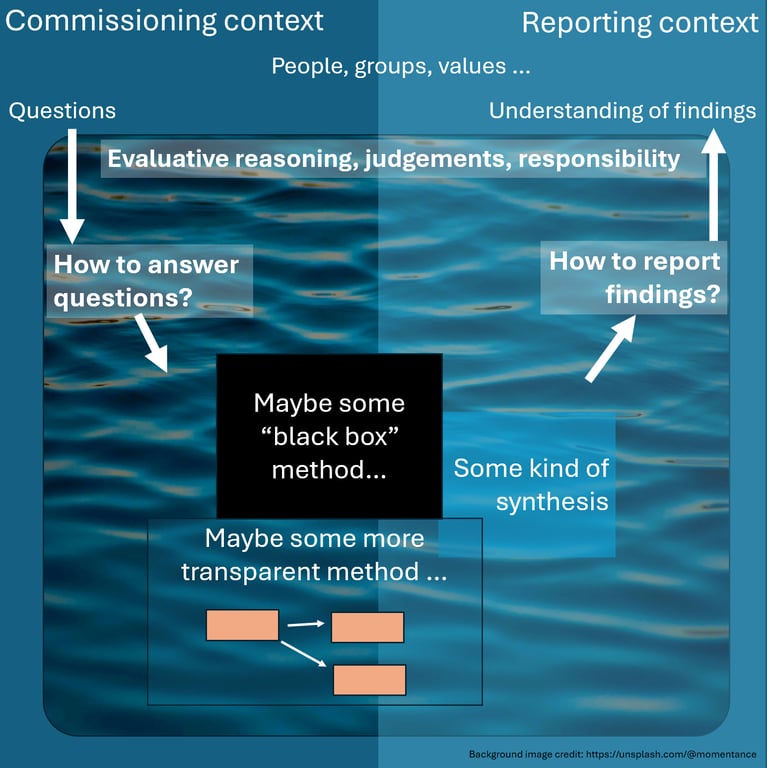
- Questions come from a context and get answered and understood in a context.
- Everything in the middle is our responsibility, as evaluators. It’s a political and ethical process. This area is full of evaluative reasoning and evaluative judgment, whether we like it or not. In fact, it is drenched in evaluative reasoning and evaluative judgment, so I have given it a watery background. This process involves, but is not limited to:
- Deciding how to get trustworthy and valid answers to those questions by constructing a workflow:, a combination of methods to answer them, which gives those questions more precise meaning.
- We might refer say to the OECD-DAC criteria, and to domain- and context-specific information, to unpack the question in a way which is transparent and which stakeholders can get behind. (In practice, we often can’t specify our method completely in advance and have to make some decisions as we go along, as long as we can explain afterwards, as transparently as possible, what we did .)
- Actually carrying out and combining the (possibly multiple) methods we choose.
- Even if and when we decide to apply some particular, well-documented, off-the-shelf method, we still have the task of monitoring and adjusting its application. Is that questionnaire validated? Does this interviewer work well with children? What should I do with this low response rate? etc. We can try to produce checklists to remind us of all these things, but who chose the checklist?
- Synthesising and reporting our findings so that they will be properly understood.
Trying to avoid this responsibility or pretend it doesn’t exist is the basic sin of evaluation.
It’s tempting to avoid it because to do so often seems cheaper, safer and easier.
We long for algorithms, decision trees, black boxes, bricolage templates, which would automate the answer to the evaluation questions. That’s understandable. And we can learn a lot from templates and decision trees and checklists. But it’s still our decision which template to use.
I say “our” because even if it’s an individual who is in charge of a single evaluation process, the construction of what is the right, fair, trustworthy, valid, accurate or useful process is a collective activity. You can’t construct meaning on your own.
Giving up and asking some guy in the street the answer to our evaluation questions is bad faith. None of us would do it. So why do we think it is ok to ask an AI?
The Black Box of Evaluative Decisions
In the very near future we’re going to see comprehensive, almost-end-to-end evaluation engines. There is a LOT of money in this market and a LOT of incentive for suppliers to sell us stuff. But however comprehensive they are, their use will still be still embedded within someone’s domain of responsibility. All that responsibility is just compressed into a smaller zone, the remaining margin around that black hole or black box. It’s less visible but it’s still there. And our findings are less trustworthy because no-one can check what we’ve done (what the AI has done). In fact, we don’t know ourselves what we’ve done. We don’t even know why the AI’s answer is an answer to the question, though it may sound like one.

You could say that even a monolithic Randomised Controlled Trial (RCT) is less of a black box than monolithic use of an AI, because even an RCT has documented methods and data and implementation and analysis logs which can be verified. The team conducting an RCT still (implicitly) says: “To the best of our knowledge and understanding of the context, we honestly believe that this method in this context will produce reasonably valid results which will be correctly understood. That’s our responsibility. Here’s how we did it …”
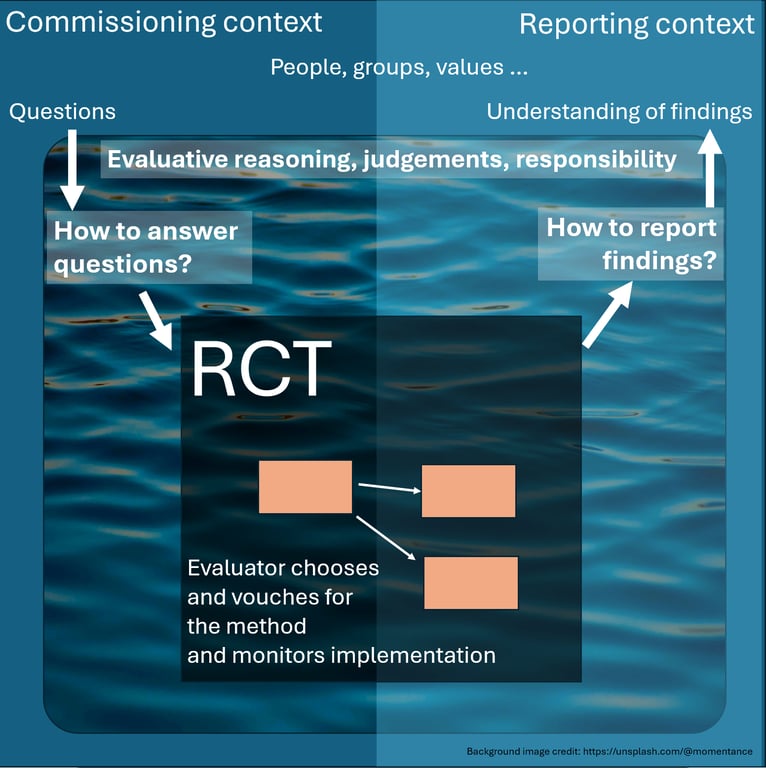
To sum up: DO take responsibility
Do | Don't |
DO Take ownership of your method and your results, whether you use an AI or not. You are the researcher / evaluator. You have decided to use this particular tool in this particular way. | DON’T Delegate responsibility to the AI. Deferring to an AI cannot replace human judgment and accountability. This isn’t a technical limitation. It isn’t about AI. |
DO unpack your understanding of how to answer the question in a way that can get consensus (or is a result of a consensus-building process). | DON’T think you can skip this step! |
DO Explain why you chose this way of working, this AI, this prompt or method. | Asking an AI the meta-question “which AI technique should I use in this situation” does not relieve you of the responsibility either. DON’T leave yourself open to the possibility that the AI was doing something you didn’t intend. |
If you’ve been told to use a particular method, DO at least set out its strengths and limitations and explain your understanding of how it should be applied in this particular context. | If you can possibly afford it, DON’T be complicit in "evaluation bad faith”: applying a method just because it’s there, without being reasonably sure how it is supposed to produce fair results. |
In my last post, I wrote about how we shouldn’t try to give complex, vague but important questions like “Is this program effective?” to an AI: instead, we can try breaking them up into many smaller steps which can be intersubjectively verified (and which can be given to an AI, or which you could have done yourself if you had the time). In this second post I have gone bit further: to frame the task of breaking down a question as also part of the collective process of giving the question a more precise meaning by agreeing how to answer it.
Endnotes
This post is based on my recent contribution to the NLP-CoP Ethics & Governance Working Group, along with colleagues Niamh Barry, Elizabeth Long and Grace Lyn Higdon. I am not very good at remembering where I nicked these ideas from, but here’s a relevant post by Florencia Guerzovich and another (of many) by Tom Aston.
The future
All this will change. As we gradually gather experience with more and more automated systems, we will probably come to trust some of them, some of the time. Will that be like trust in magic, or trust in science? Will it be only (increasingly anti-democratic) mega-corporations which broker that trust?
Causal mapping
At Causal Map Ltd, we’ve found that highlighting and then aggregating causal links is a great and relatively generic path from text data to the brink of evaluative judgment. We’re also working on ways to make workflows accessible. See how we currently use AI in Causal Map here. More on that in the final post in this series.
Philosophy
The challenge of evaluator responsibility is a thoroughly existential or transcendental dilemma: I can rely on a template, but which template? There is no ultimate template for choosing all templates. I think Kierkegaard would say that we (should) make evaluation judgements “in fear and trembling”. I think Sartre might have called the temptation in evaluation to give up responsibility "evaluation bad faith”.
This kind of thinking moves the focus from impersonal evaluation methods to the person of the evaluator(s), our socialisation into shared, living methods, and perhaps that is where Michael Polanyi’s idea of tacit knowledge comes in.
This post was originally published by Steve Powell on LinkedIn and has been republished here. See the original article here

